Projects you can open right now
Five live, self-contained apps spanning the AI-product lifecycle: build, evaluate, experiment, monitor, explain. Each runs on synthetic or real public data, so there's nothing proprietary. Just click and explore.
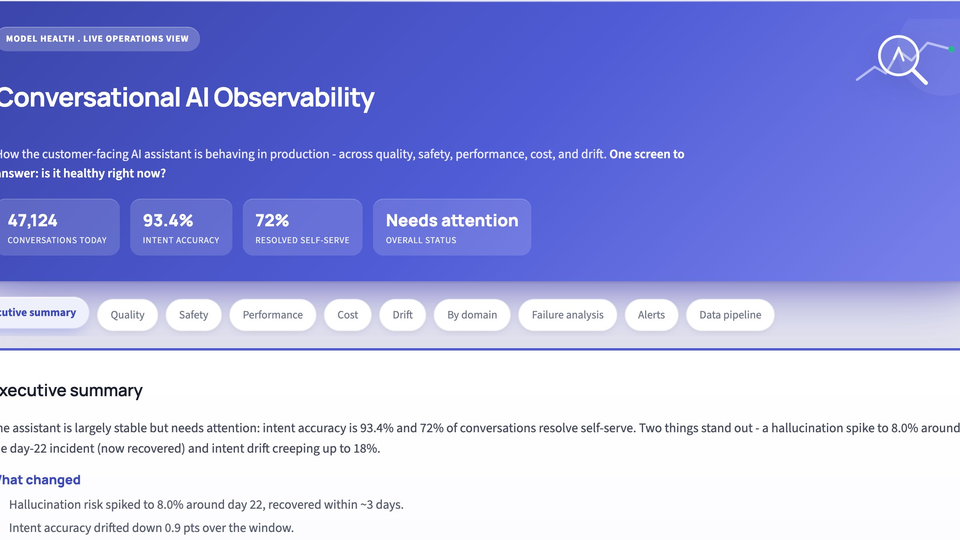
LLM Observability & Evals
Model-health monitoring across quality, safety, performance, cost & drift, on a SQL-backed pipeline with alerting and PDF/PPTX export.
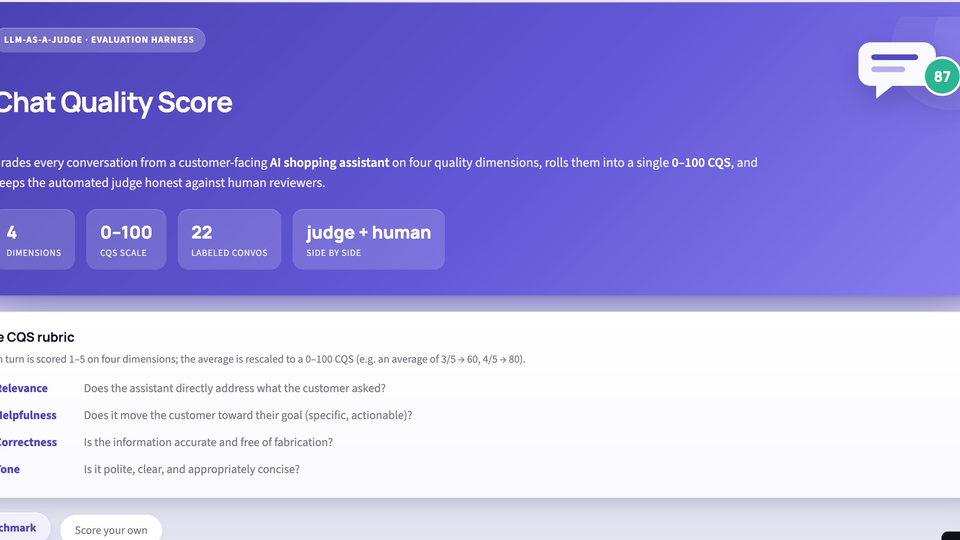
Chat Quality Score (CQS)
An LLM-as-a-judge evaluation that scores conversations on a 4-dimension rubric, calibrated against human labels.
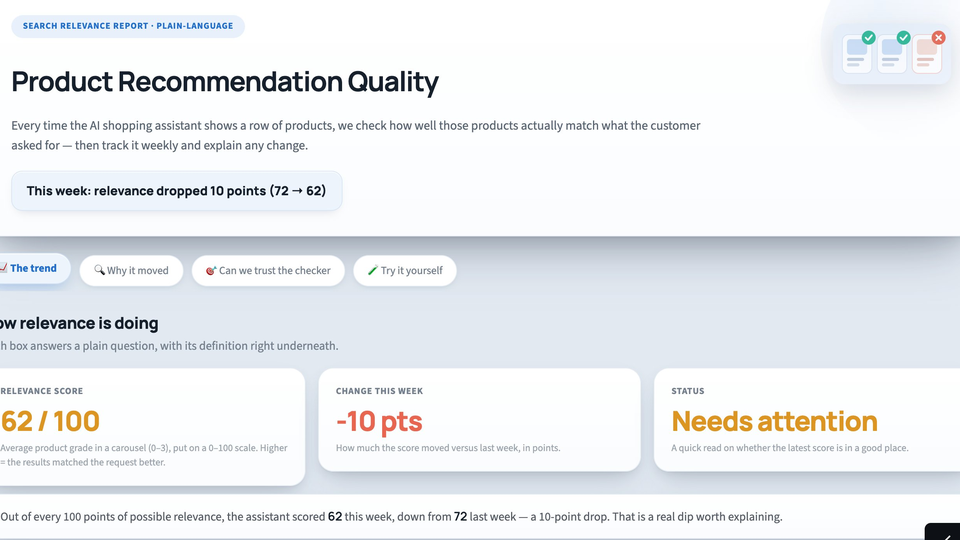
Product Recommendation Quality
Tracks AI recommendation relevance week over week and surfaces the drivers behind any change.
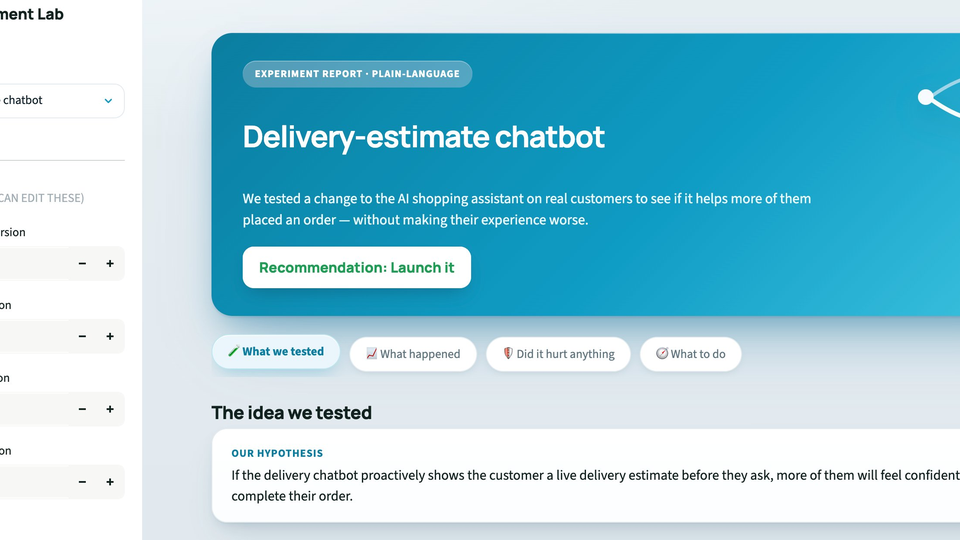
A/B Experimentation Framework
Hypothesis design, randomization, guardrail metrics, and ship / iterate / stop decisioning.

LedgerIQ — Finance RAG Agent
A finance-ops RAG agent over two sources (real SEC EDGAR filings and FP&A planning documents) with grounded, cited answers that refuse when out-of-corpus, plus token-minimization controls and MCP retrieval servers.